
Atlanta's growth story sounds great in board meetings. On the ground, it creates hard infrastructure choices fast. In 2024, metro Atlanta's net leased data-center space increased by 706 megawatts, and nearly 2,160 megawatts of development was under construction, according to GovTech's reporting on CBRE market data. That isn't just a real-estate headline. It changes how local companies should think about power, connectivity, build timelines, and the cost of replacing aging hardware.
That's the part many scaling guides miss. They focus on cloud architecture, headcount planning, and software tooling inside the business. Those matter. But in Metro Atlanta, external constraints are now shaping internal IT decisions just as much as your own roadmap.
A growing company can usually work around one bottleneck. It struggles when several hit at once. Utility lead times get less predictable. Industrial space gets tighter. Skilled infrastructure staff become harder to hire and retain. Old server rooms that were “good enough” for a smaller operation turn into risk centers. And when refresh cycles accelerate, the pile of retired equipment grows right alongside production demand.
Atlanta's Growth Is Great for Business but a Stress Test for IT
If you're expanding in Atlanta, the key mistake is treating infrastructure as a purely internal function. It isn't. Your network closet, rack footprint, cloud bill, and refresh schedule now sit inside a regional market that's under visible strain.
The growth is real, and so is the friction. Data-center development is pulling on the same power, land, permitting, and labor systems that support ordinary business expansion. At the same time, the metro area is adding people, buildings, traffic, and utility demand. A company can have a sound IT roadmap and still run into delays because the surrounding environment has become less forgiving.
Practical rule: In Atlanta, assume external capacity constraints will affect internal IT timelines earlier than your team expects.
That changes how mature IT planning should look. Instead of asking only “What systems do we need next?” the better question is “What can this market support on the timeline we want?”
Three decisions usually separate companies that scale cleanly from companies that stall:
- Power planning first: Don't approve infrastructure growth without confirming utility realities, facility limits, and cooling implications.
- Flexibility over permanence: Keep room to split workloads across on-prem, colocation, and cloud instead of betting everything on one model.
- Lifecycle discipline: Treat procurement, deployment, redeployment, and disposal as one chain. If the back end is sloppy, the front end gets expensive.
The Atlanta IT infrastructure challenges in rapid growth aren't abstract. They show up in delayed projects, crowded telecom pathways, emergency hardware buys, overworked admins, and compliance exposure from equipment that should've been retired properly months ago.
The Perfect Storm Driving Atlanta's Infrastructure Strain
Atlanta's growth is colliding with three hard constraints at once: power availability, real estate that can support technical loads, and rising utility and build-out costs. Those pressures do not stay outside the data center. They shape what your IT team can deploy, where it can go, and how long it stays viable before the next upgrade cycle.
Data-center demand is reshaping the local equation
The clearest pressure point is data-center expansion across metro Atlanta. As noted earlier, the market added an unusual amount of leased capacity in 2024, with a large construction pipeline still underway. That kind of growth pulls on the same substations, feeder capacity, construction crews, and fiber routes that mid-market and enterprise companies depend on for ordinary expansion.
The practical mistake I still see is assuming “Atlanta has plenty of data centers” means capacity is easy to get. It often is not, at least not in the location, power density, timeline, or contract structure a growing company wants. A cage may be available, but not with the redundant power path you need. A suite may exist, but the utility upgrade can push occupancy out by months. A building may look attractive on rent, then fail the load, cooling, or carrier-diversity check once engineering gets involved.
That changes internal IT decisions fast. Teams that expected to add on-prem hardware in one office may need to split workloads across cloud and colocation. Disaster recovery plans may need a different geography than originally budgeted. Hardware refresh schedules may need to tighten because extending old equipment becomes riskier when replacement capacity is less flexible.
Real estate and utility pressure raise the cost of getting infrastructure wrong
Atlanta's commercial growth has made technical real estate more selective. Not every office, warehouse, or mixed-use property can support higher rack density, added cooling, battery systems, or generator work without major capital expense. Companies discover this late, usually after signing a lease or approving a floor plan based on square footage instead of facility limits.
Utility cost pressure makes the same point from another angle. More load means more than a higher monthly bill. It can trigger panel upgrades, cooling redesign, electrical studies, landlord negotiations, and downtime planning. For a fast-growing company, one bad assumption about facility readiness can turn a simple expansion into a six-figure project.
This is why infrastructure planning in Atlanta has to include facilities, finance, and operations early. IT cannot be the last team asked to “make the space work.”
For firms reviewing connectivity options, local telecom services in Atlanta should be evaluated against actual building entry paths, carrier availability, and route diversity, not just quoted bandwidth and price.
External strain turns into lifecycle pressure inside the business
Once external constraints tighten, equipment lifecycle management stops being an administrative task and becomes a scaling control. If power is harder to secure and build-outs take longer, companies hold aging gear in production longer than planned. If floor space is tight, retired equipment piles up in closets, MDF rooms, and storage areas because nobody wants to pull the trigger on disposition during an expansion push.
That creates a second problem. Deferred retirement increases failure risk, but sloppy retirement creates compliance and security exposure. I have seen growing firms spend heavily on new infrastructure while old servers, switches, and endpoint devices sit untracked in the same building, still carrying data and still showing up on audit lists.
The firms that handle Atlanta's external strain best treat infrastructure as a full lifecycle decision. They validate power and space before procurement, keep deployment options flexible, and retire equipment on schedule instead of letting obsolete assets consume space, power, and attention.
In Atlanta, infrastructure strain rarely starts with a server. It usually starts with a market constraint that forces bad technical compromises downstream.
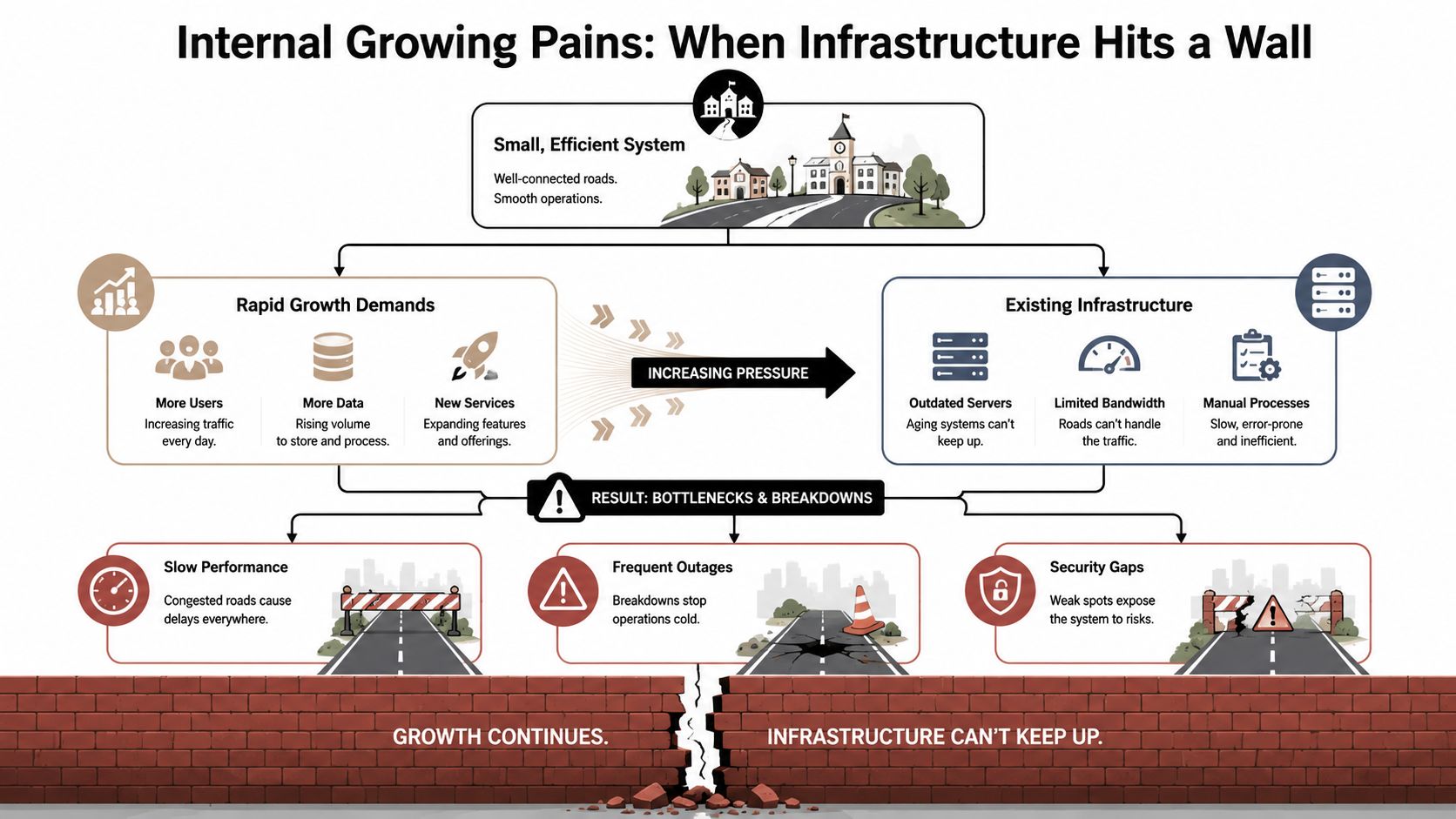
Internal Growing Pains When Your Current Infrastructure Hits a Wall
Internal failures usually show up before leadership calls them failures. In Atlanta growth-stage companies, the early signal is drag. Core systems still run, but they run with less margin, less visibility, and less room for error.
What the wall looks like inside a growing company
The pattern is familiar. File transfers stretch out. Backups collide with production hours. Virtual desktops get inconsistent. An ERP or warehouse application that handled last year's demand starts timing out during ordinary daily use. Strained IT teams often add point fixes and call it scaling.
It is not scaling. It is deferred redesign.
I see the same failure points in fast-growing Atlanta environments, especially in firms adding headcount, new locations, or heavier warehouse and edge workloads faster than their original design anticipated:
- Network saturation: Internet circuits, site-to-site links, and switching fabrics carry more east-west traffic, cloud traffic, and voice traffic than they were sized for.
- Compute exhaustion: Older hosts stay in service because refresh projects slip, support contracts get extended, and no one wants to touch stable but undersized clusters during an expansion.
- Storage contention: Retention grows, recovery expectations tighten, and the storage design stays the same. Performance drops first. Recovery pain shows up later.
- Operational sprawl: Temporary fixes become permanent. Teams inherit too many appliances, scripts, and one-off systems to support cleanly.
The budget problem is usually self-inflicted. Companies spend small amounts in too many places instead of making one or two structural fixes that lower support load for the next three years.
Reactive IT creates security and compliance gaps
Under pressure, infrastructure teams protect uptime first. That is a rational decision in the moment. It also creates audit problems fast.
Patching windows shrink. Asset records drift. Admin exceptions stay in place longer than planned. Retired laptops, drives, switches, and servers end up in storage rooms because no one has a documented path to sanitize, track, and remove them during a busy quarter. A rushed refresh with weak tracking can create as much trouble as a delayed refresh.
That is why disciplined IT asset management best practices matter during expansion. A current inventory, clear ownership, lifecycle dates, and documented retirement workflows help IT decide what to keep, what to replace, and what to dispose of before old equipment turns into a security finding.
Thin staffing turns technical debt into operational risk
Atlanta's growth adds demand for engineers, facilities contacts, project managers, and support staff across the market. As noted earlier, regional population growth is part of that pressure. The practical effect inside a company is simple. Infrastructure strain is manageable with depth on the bench. It gets dangerous when critical knowledge lives with one systems engineer, one network lead, or one outside contractor.
I have watched growing firms approve hardware but wait too long to secure the people needed to implement it well. If you need development support while your internal team is buried in infrastructure work, firms such as Hire Developers can fill a delivery gap. That does not replace internal operational ownership, though. Someone still has to control standards, documentation, change windows, and handoff quality.
Here are the responses that usually create more pain than they remove:
| Common response | Why it fails |
|---|---|
| Keep extending old hardware | Failure risk rises, vendor support gets thinner, and emergency replacement costs more |
| Add more SaaS without integration discipline | Complexity shifts into identity, support, reporting, and data governance |
| Delay decommissioning | Old assets keep consuming space, power, and audit attention while still carrying data risk |
| Hire only after systems break | Recruiting and onboarding do not happen on the same timeline as an outage |
If senior admins spend more time keeping aging equipment alive than designing the next stable state, growth has already outpaced the infrastructure model.
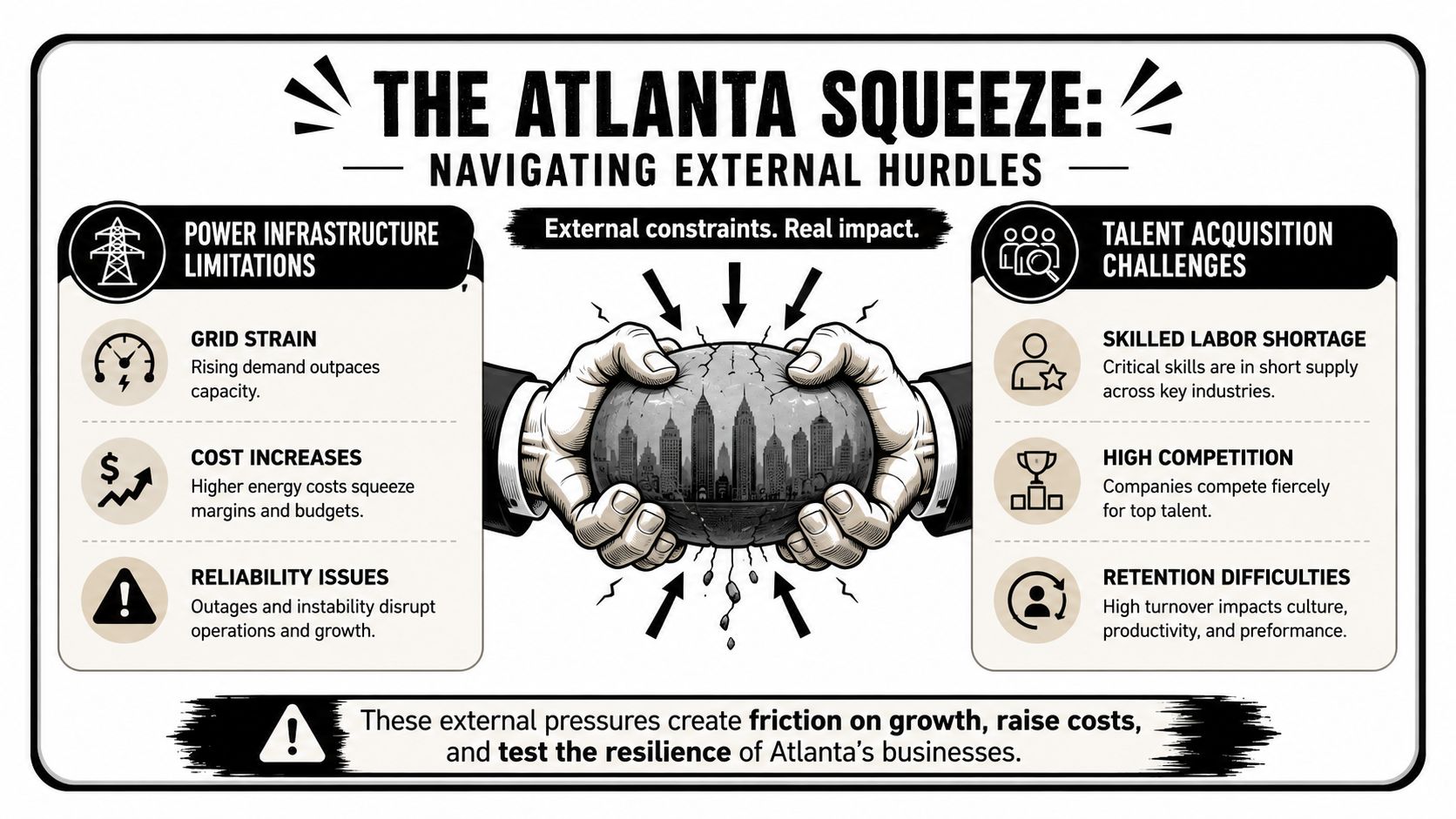
The Atlanta Squeeze Navigating External Power and Talent Hurdles
The hardest conversations with expanding companies in Atlanta now tend to revolve around one issue. Not software. Not user adoption. Basic physical support for digital growth.
Power is no longer a background assumption
Deloitte reports that U.S. AI data-center power demand could rise from 4 GW in 2024 to 123 GW by 2035, and 72% of surveyed power-company and data-center executives rated grid capacity as very or extremely challenging, according to Deloitte's analysis of AI-era infrastructure demand. For Atlanta businesses, the takeaway is straightforward. Don't assume power is easy to secure, easy to expand, or cheap to ignore.
That hits companies in different ways depending on size:
- Midmarket firms run into upgrade decisions earlier than expected when office or warehouse facilities weren't designed for denser edge workloads.
- Enterprises find that timing matters as much as budget. A funded project can still wait on physical capacity.
- Colocation users face a more selective market, especially for workloads with heavier power and cooling requirements.
Cooling strategy belongs in the same conversation. If a workload needs denser racks or specialized thermal management, the facility question becomes operational, not cosmetic.
Talent competition changes delivery options
Atlanta companies also have to adjust how they source technical labor. The old model was simple. Hire local for everything. In a tighter market, that can slow projects and raise the risk of underqualified placement for specialized roles.
A practical response is to separate functions by proximity. Keep hands-on work local. That includes facilities coordination, rack and stack, telecom turn-up, and hardware chain-of-custody tasks. Expand your search for software, DevOps, QA, and support engineering where location matters less. Teams that need extra bench strength often use platforms like Hire Developers when local recruiting cycles don't match delivery deadlines.
Reliability planning has to be local
Weather, utility events, and site conditions shape uptime more than many business plans admit. In North Fulton and surrounding corridors, site selection should include local operating realities, seasonal demand patterns, and service access considerations. Even something as simple as reviewing weather in Alpharetta, Georgia is part of sensible planning when your infrastructure, logistics, and field work are tied to a specific submarket.
A short decision screen helps:
- If the workload is latency-sensitive, place it where network path and facility reliability are proven.
- If the workload is variable, use cloud elasticity and keep local infrastructure lean.
- If the workload is compliance-heavy, design chain-of-custody and disposal processes before deployment starts.
Proactive Strategies for Scaling Your IT Infrastructure
The companies that handle Atlanta IT infrastructure challenges in rapid growth best usually do one thing differently. They stop treating infrastructure as a series of emergency purchases and start treating it as an operating model.
Operational moves that buy flexibility
Start with architecture. Most growing firms shouldn't force every workload into one destination. A hybrid model is usually more durable. Keep stable, predictable systems where they run efficiently. Move bursty demand and development environments into cloud platforms where you can scale without waiting on local facility changes. Use automation for provisioning, patching, monitoring, and configuration control so your team spends less time on repetitive support.
Migration discipline matters too. If you're moving out of a cramped server room or redesigning application placement, follow proven data center migration best practices instead of improvising around maintenance windows. Sequence matters. Dependency mapping matters. Rollback planning matters.
A good operating pattern looks like this:
- Standardize first: Reduce exceptions before you add capacity.
- Instrument the environment: Use monitoring that shows power, cooling, network, and system behavior together.
- Design for redeployment: Buy hardware that can be reassigned internally before retirement.
Don't scale broken patterns. They become more expensive once you automate them.
Financial planning that reflects local reality
Georgia's Public Service Commission has begun requiring new high-power-draw customers, including data centers, to cover more of the grid upgrade costs tied to their demand, as described by Georgia Tech's analysis of the data-center building boom. That should change how businesses budget for expansion.
If your footprint is growing, treat energy-related cost exposure as a planning input, not a surprise line item. Build scenarios for utility upgrades, denser cooling requirements, and longer infrastructure lead times. Compare CapEx-heavy refreshes against service models that preserve flexibility if business demand changes.
For staffing, many firms now mix local infrastructure talent with distributed specialists. If you need to extend engineering capacity without adding every role in Atlanta, one practical option is to Hire LATAM talent for functions that don't require physical site presence.
Compliance controls that hold up during fast change
Growth tends to break documentation first. Access rights drift. Asset records lag. Disposal gets delayed because new deployment always seems more urgent than retirement. That's a mistake.
Use a simple compliance backbone:
- Maintain a live asset register with owner, location, role, and disposition state.
- Tie decommissioning to project closure so retired equipment doesn't sit untracked.
- Require approved sanitization and destruction workflows before anything leaves custody.
- Keep audit artifacts for wipes, transfers, resale, recycling, and destruction.
If you need local support for retired hardware streams, Montclair Crew Recycling is one Atlanta-area option for equipment pickup, audit support, certified data destruction, and environmentally compliant disposition. The point isn't the vendor name. The point is that disposal needs to be planned at the same time as procurement.
Closing the Loop with Smart IT Asset Disposition
Fast growth creates a hidden byproduct. Old equipment piles up faster than most organizations expect.
Why ITAD belongs in infrastructure planning
With cooling alone accounting for up to 40% of data-center electricity demand, and Atlanta having 2,160 megawatts of new capacity under construction, the amount of hardware being deployed and eventually retired makes strategic disposition planning essential, according to AJC's reporting on Atlanta's data-center growth and infrastructure pressure.
Most companies still treat IT asset disposition as the cleanup phase. That's too late. By the time old servers, laptops, storage arrays, and telecom gear are sitting in a back room, the main risks are already in motion. Nobody is fully sure what data remains on them. The inventory count may be off. Finance may not know what can be resold, recycled, or written off. Compliance may not have the documentation it needs.
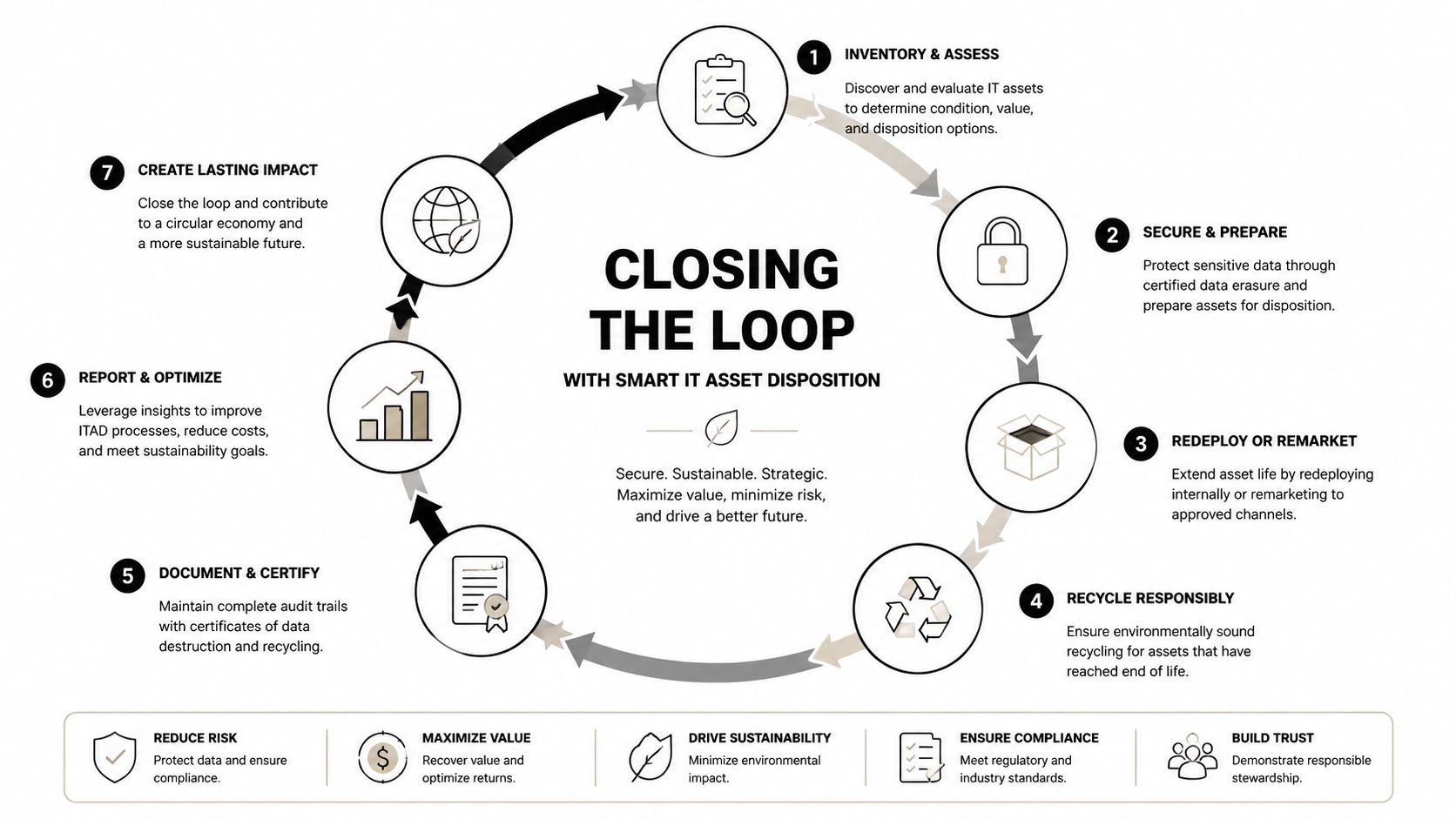
What good disposition looks like
A strong ITAD program is boring in the right way. It's documented, repeatable, and tied to the rest of operations.
The basics are straightforward:
- Identify assets early: Tag what's leaving production before the cutover, not after.
- Protect data first: Sanitization and destruction steps should be documented and verifiable.
- Sort by disposition path: Some assets can be redeployed. Some may have resale value. Some should go directly to recycling.
- Keep certificates and reports: Audit trails matter for internal governance and external review.
Retired hardware is still part of your risk surface until you can prove otherwise.
The budget case is stronger than most teams think
Bad disposal is expensive in quiet ways. Storage rooms fill up. Field teams lose time moving dead equipment around. Projects stall because the old environment was never fully cleared. Procurement buys replacements without understanding what can be recovered from existing stock. Then legal or compliance gets involved after the fact.
A smart program helps on three fronts at once:
| Area | What strategic ITAD improves |
|---|---|
| Risk | Secure data destruction and documented chain of custody |
| Finance | Value recovery, cleaner inventories, better refresh planning |
| Sustainability | Responsible recycling and less landfill waste |
For Atlanta businesses with active refresh cycles, branch consolidations, or data-center changes, a local IT asset disposition service in Atlanta, GA can simplify the handoff from decommissioning to secure final disposition. That's especially useful when equipment includes mixed categories such as servers, laptops, networking gear, and storage devices that need different handling.
A mature infrastructure strategy doesn't end when new equipment goes live. It ends when the equipment it replaced has been tracked, sanitized, removed, documented, and processed correctly.
If your company is expanding in Metro Atlanta and your retired hardware process is lagging behind your deployment pace, Montclair Crew Recycling can help close that gap with local pickup, secure data destruction, asset audit support, and environmentally compliant IT equipment disposition.